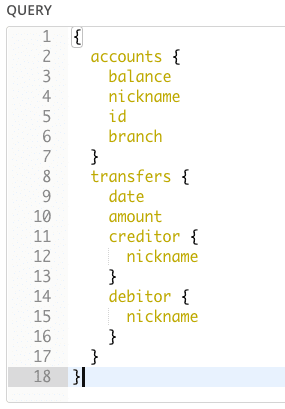
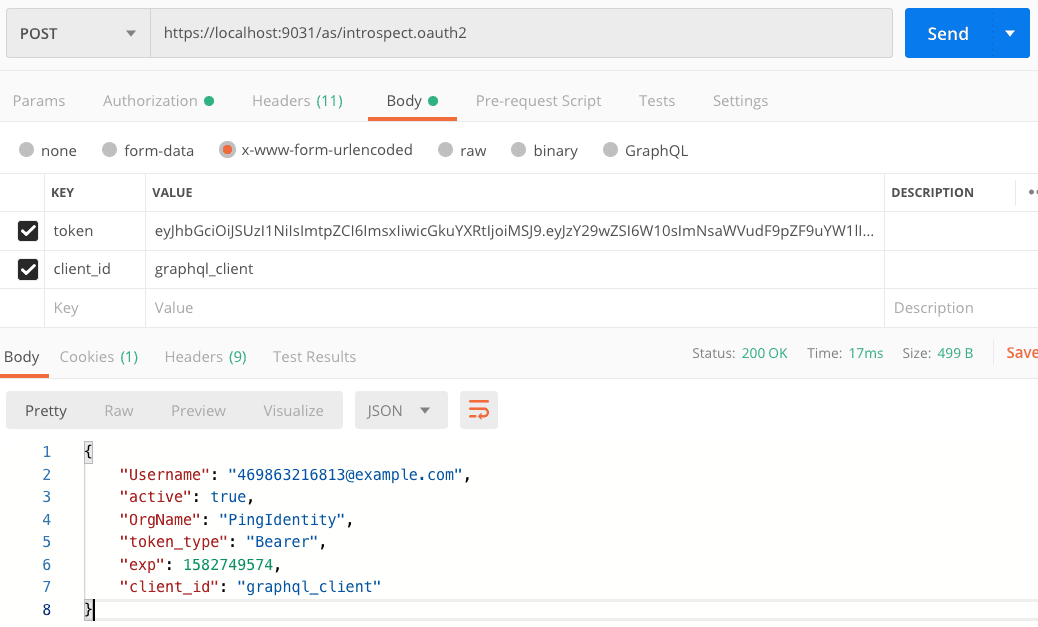
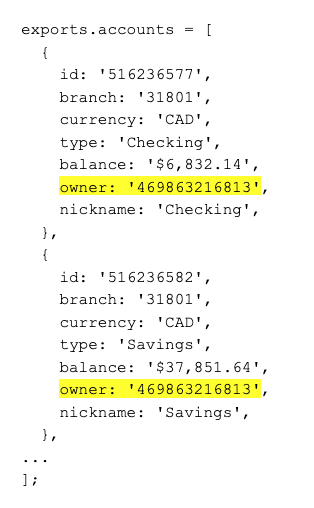
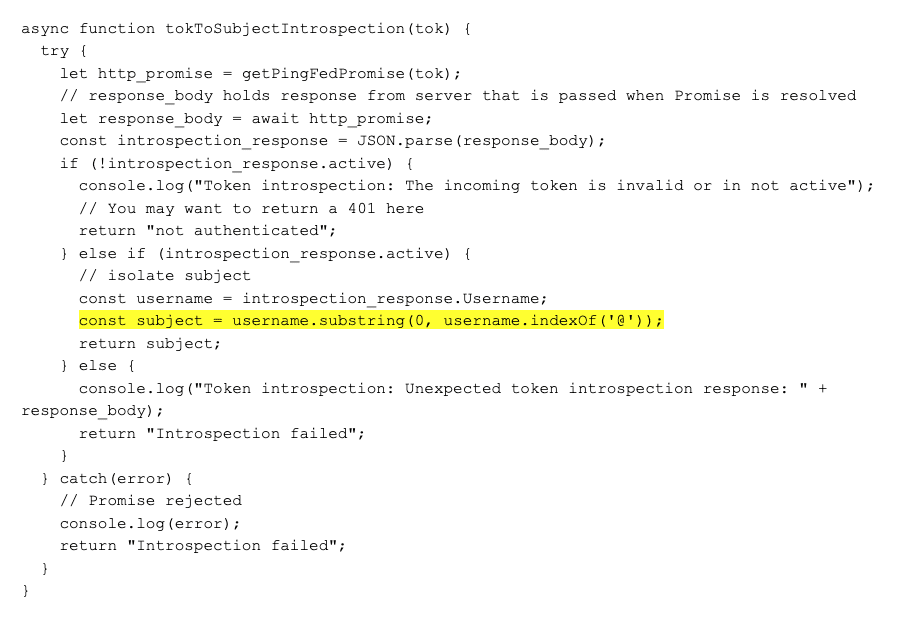
GraphQL is an emerging open-source API standards project that front-end developers love because it puts them in control. Developers are no longer restricted to a fixed set of API methods and URI patterns but instead get to customize their queries in whichever ways best suit their applications. Because of this added control, and because of other benefits around non-breaking version upgrades and performance optimizations, GraphQL is on its way to becoming omnipresent among web APIs.
But security and access control are often not top of mind for API developers. Since GraphQL adoption is an emerging trend (it originated with Facebook in 2012 and moved under the Linux Foundation umbrella in late 2018), well-established practices are not yet available on how to apply access control to a GraphQL API. This multi-part blog series is going to take us through these challenges and provide some guidance to help ensure any new or existing GraphQL deployment is well protected.